AI极简科普(上):AI前世与今生
AI极简科普(上):AI前世与今生
From:有光AI
Date:2024年8月10日
在这个科技飞速发展的时代,人工智能(AI)无疑是最热门的话题之一。无论是在新闻报道里,还是在日常生活中,AI 这个词频频出现,仿佛它已经成为我们生活中不可或缺的一部分。
那么,究竟什么是 AI?这个神秘而强大的技术究竟能带来什么?今天,我们就来揭开 AI 的神秘面纱。
故事的开端
大家可以思考这样一个问题:“机器能思考吗?”
每个故事都有个开头,对 AI 来说也是一样。但 AI 能选择的开头太多了。
我们可以选择从古希腊开始,铁匠之神赫菲斯托斯(Hephaestus)拥有赋予金属物品生命的能力。
.PNG)
我们可以选择从18世纪开始,苏格兰的詹姆斯·瓦特(James Watt)为正在建造的蒸汽机设计了一个巧妙的自动控制系统——调速器,为现代控制理论奠定了基础。那时也掀起了自动机器装置狂热的开始,那些小型自动机器装置被设计得无比精妙,有一种被赋予生命的错觉。

-20241111143739748.png)
我们也可以选择从19世纪初开始,年轻的玛丽·雪莱(Mary Shelley)被恶劣的天气困在瑞士的一栋别墅里,创作了科幻小说开山之作——《弗兰肯斯坦》。
.PNG)
甚至,我们可以选择从19世纪70年代开始,秀丽隐杆线虫开始被研究者用作模式生物。秀丽线虫、果蝇、鱼、小鼠等模式生物的研究,为探索生物大脑运作机理提供了模板,也为类脑智能的研究铺平了道路。
.PNG)

看起来 AI 的开端可以有很多选择,作为一门学科,其思想可以追溯到20世纪初,甚至古希腊时期。逻辑学、控制论和早期的机械自动化设备也为人工智能的发展奠定了思想基础。但实际上,AI故事的开端与计算机的开端应该是一致的。所以我们可以从这里讲起:1935年,剑桥大学国王学院,艾伦·图灵(Alan Turing)。

图灵这个名字相信多数人并不陌生。
20世纪40年代末至50年代初,第一台计算机的出现引发了一场公开辩论,辩论主题就是计算机的潜力如何。当时,公众辩论中经常提到“机器做不到思考、推理或者进行类似创造性的工作”,图灵对这样的说法非常恼火,他想让那些认为“机器不能思考”的人彻底闭嘴,于是提出了一个实验,就是大名鼎鼎的图灵测试。这个实验的流程是由一位询问者写下自己的问题,随后将问题发送给在另一个房间中的一个人与一台机器,由询问者根据他们所作的回答来判断哪一个是真人,哪一个是机器。自1950年第一次提出以来,图灵测试一直具有巨大的影响力,直至如今,它仍然是一个严肃的研究课题。

图灵测试可以作为判断机器是否具有智能的一个标准,它的出现标志着人类开始系统性地探索和定义机器智能,是AI发展史上一个重要的里程碑。然而,它更多地被视为评估机器智能的一个标准,而不是人工智能研究的起点。
在1935年,图灵还是剑桥大学数学系的一名学生,那个时候他给自己定下了一个巨大的挑战——判定问题。这是当时最重要的终极数学问题之一。

关于判定问题这里就不展开讲了,感兴趣的小伙伴们可以去自行深入了解,对我们大多数老百姓来说只需要知道,为了解决这样的问题,图灵的想法非常颠覆传统,他想通过发明一台机器来解决一个艰深的数学问题,这个机器就是“图灵机”,计算机的前身。图灵机的概念是现代计算机科学的基础,也是理解人工智能中算法和计算能力的一个重要起点。
而人工智能作为一门独立学科的正式诞生,是在1956年。这一年在达特茅斯学院举行的会议上,支持图灵的美国计算机科学家提出了现在广为人知的《达特茅斯人工智能夏季研究项目提案》,“人工智能”这个术语首次在这份提案中诞生。这次会议聚集了一批对机器模拟智能感兴趣的科学家,标志着人工智能研究的正式起步。


这便是AI故事的开端。
故事的发展
AI的发展史相比于一般传统学科领域来说不长,但也发生了很多故事,经历了很多阶段。篇幅有限,这里就不详细展开了。
如今,我们谈到AI,多数时候在谈“大模型”。而在大模型成为AI领域的主流之前,AI也经历了一些重要的研究和发展阶段。这里我们从3个角度去看。
(注意⚠️接下来会有大量的专业术语,不感兴趣的小伙伴可以看个大体的发展,切勿细看各种词汇以致丧失阅读兴趣⚠️)
角度一
如果放眼整个AI领域的发展,我们可以大体分为这样几个阶段:
| 阶段 | 周期 | 方法 | 技术 | 例子 |
|---|---|---|---|---|
| 符号主义 (符号推理) | 1950s-1970s | 基于逻辑和规则的推理系统,使用符号表示知识。 | 如命题逻辑、谓词逻辑和LISP编程语言。 | 艾伦·图灵的图灵测试和约翰·麦卡锡的LISP语言。 |
| 连接主义 | 1940s-1980s | 受生物神经网络启发,使用人工神经网络来模拟大脑功能。 | 多层感知器、反向传播算法。 | 弗兰克·罗森布拉特的感知机和杰弗里·辛顿的反向传播算法。 |
| 专家系统 | 1980s | 模拟专家决策过程,使用大量规则和知识库。 | 基于规则的系统、知识表示和推理。 | MYCIN、XCON等早期专家系统。 |
| 机器学习 | 1990s-2000s | 从数据中学习模式和规律,而不需要明确编程。 | 决策树、支持向量机、随机森林等。 | 机器学习算法开始广泛应用于图像识别、自然语言处理等领域。 |
| 深度学习 | 2010s至今 | 使用多层神经网络来学习复杂的数据表示。 | 卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)等。 | 深度学习在图像识别、语音识别和自然语言处理等领域取得重大突破。 |
| 大模型时代 | 近年 | 使用大规模数据集和计算资源训练大型神经网络模型。 | Transformer架构、自监督学习、预训练语言模型(如BERT、GPT)。 | 大型语言模型如GPT-3、DALL-E等,它们在文本生成、图像生成等方面展现出强大的能力。 |
-
符号主义(1950s-1970s)
-
方法:基于逻辑和规则的推理系统,使用符号表示知识。
-
技术:如命题逻辑、谓词逻辑和LISP编程语言。
-
例子:艾伦·图灵的图灵测试和约翰·麦卡锡的LISP语言。

-
-
连接主义(1940s-1980s)
-
方法:受生物神经网络启发,使用人工神经网络来模拟大脑功能。
-
技术:多层感知器、反向传播算法。
-
例子:弗兰克·罗森布拉特的感知机和杰弗里·辛顿的反向传播算法。
-
-
专家系统(1980s)
- 方法:模拟专家决策过程,使用大量规则和知识库。
- 技术:基于规则的系统、知识表示和推理。
- 例子:MYCIN、XCON等早期专家系统。
-
机器学习(1990s-2000s)
- 方法:从数据中学习模式和规律,而不需要明确编程。
- 技术:决策树、支持向量机、随机森林等。
- 例子:机器学习算法开始广泛应用于图像识别、自然语言处理等领域。
-
深度学习(2010s至今)
- 方法:使用多层神经网络来学习复杂的数据表示。
- 技术:卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)等。
- 例子:深度学习在图像识别、语音识别和自然语言处理等领域取得重大突破。
-
大模型时代(近年)
-
方法:使用大规模数据集和计算资源训练大型神经网络模型。
-
技术:Transformer架构、自监督学习、预训练语言模型(如BERT、GPT)。
-
例子:大型语言模型如GPT-3、DALL-E等,它们在文本生成、图像生成等方面展现出强大的能力。

-
角度二
如果以生物学的角度,可以大体分为这样几个阶段:
- 启蒙阶段(古代 - 20世纪初):启发于生物智能
人类对智能行为的观察和模仿,早期自动机的概念。
-
机械化阶段(中世纪 - 19世纪末):仿生学
机械装置的制造,尝试模拟生物的运动和行为。
-
算法化阶段(20世纪40年代 - 50年代):神经网络的早期模型
图灵机和早期神经网络模型的提出。
-
学习与适应阶段(20世纪50年代 - 80年代):机器学习和早期神经网络
机器学习概念的探索,感知机和多层神经网络的研究。
-
进化阶段(20世纪80年代 - 90年代):遗传算法和进化计算
遗传算法和其他进化计算技术的提出和应用。
-
深度学习阶段(21世纪初 - 现在):深度神经网络的兴起
深度学习技术的发展,特别是2006年以后深度神经网络在多个领域的突破。
-
自主智能阶段(21世纪10年代 - 现在):自主系统和智能代理
自动驾驶汽车、智能机器人等自主系统的快速发展。
-
整合与共生阶段(正在进行中):人机协作和增强智能
人工智能与人类协作的探索,增强智能、通用人工智能的发展。
角度三
如果从“模型”的层面,我们又可以大体分为这样几个时期:
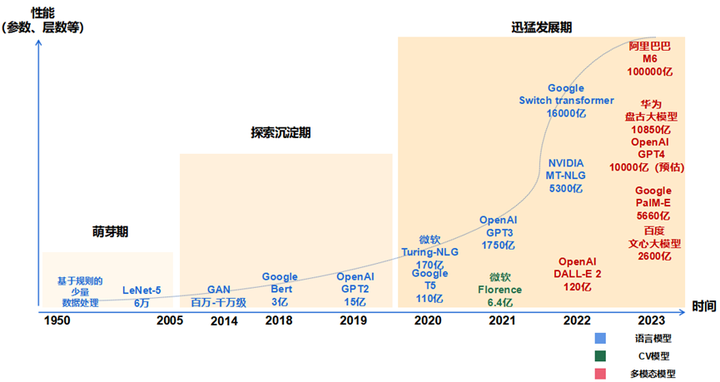
- 萌芽期(1950-2005):以 CNN 为代表的传统神经网络模型阶段
- 1956 年,从计算机专家约翰·麦卡锡提出“人工智能”概念开始,AI 发展由最开始基于小规模专家知识逐步发展为基于机器学习。
- 1980 年,卷积神经网络的雏形 CNN 诞生。
- 1998 年,现代卷积神经网络的基本结构 LeNet-5 诞生,机器学习方法由早期基于浅层机器学习的模型,变为了基于深度学习的模型,为自然语言生成、计算机视觉等领域的深入研究奠定了基础,对后续深度学习框架的迭代及大模型发展具有开创性的意义。
- 探索沉淀期(2006-2019):以 Transformer 为代表的全新神经网络模型阶段
- 2013 年,自然语言处理模型 Word2Vec 诞生,首次提出将单词转换为向量的“词向量模型”,以便计算机更好地理解和处理文本数据。
- 2014 年,被誉为 21 世纪最强大算法模型之一的 GAN(对抗式生成网络)诞生,标志着深度学习进入了生成模型研究的新阶段。
- 2017 年,Google 颠覆性地提出了基于自注意力机制的神经网络结构——Transformer 架构,奠定了大模型预训练算法架构的基础。
- 2018 年,OpenAI 和 Google 分别发布了 GPT-1 与 BERT 大模型,意味着预训练大模型成为自然语言处理领域的主流。在探索期,以 Transformer 为代表的全新神经网络架构,奠定了大模型的算法架构基础,使大模型技术的性能得到了显著提升。
- 迅猛发展期(2020-至今):以 GPT 为代表的预训练大模型阶段
- 2020 年,OpenAI 公司推出了GPT-3,模型参数规模达到了 1750 亿,成为当时最大的语言模型,并且在零样本学习任务上实现了巨大性能提升。随后,更多策略如基于人类反馈的强化学习(RLHF)、代码预训练、指令微调等开始出现, 被用于进一步提高推理能力和任务泛化。
- 2022 年 11 月,搭载了GPT3.5的 ChatGPT横空出世,凭借逼真的自然语言交互与多场景内容生成能力,迅速引爆互联网。
- 2023 年 3 月,最新发布的超大规模多模态预训练大模型——GPT-4,具备了多模态理解与多类型内容生成能力。在迅猛发展期,大数据、大算力和大算法完美结合,大幅提升了大模型的预训练和生成能力以及多模态多场景应用能力。如 ChatGPT 的巨大成功,就是在微软 Azure 强大的算力以及 wiki 等海量数据支持下,在 Transformer 架构基础上,坚持 GPT 模型及人类反馈的强化学习(RLHF)进行精调的策略下取得的。
需要注意的是,不管何种角度,这些阶段并不都是完全独立的,而是相互交织和重叠的。比如,即使在深度学习阶段,遗传算法和其它早期技术仍然在一些领域中发挥作用。另外,AI是一个快速发展的领域,新的发展和变化可能随时出现。
参考资料
维基百科
《人工智能全传》——[英]Michael Wooldridge
《从 AIGC 看人机交互新范式——人机共生》——焰
......
评论